在go标准库外实现比go标准库更好的arena
目录
此博客介绍笔者是如何在go标准库外实现比go标准库更好的arena。
背景
arena是一种内存管理方法,从中分配的内存可以被同时释放,适合在一组object的生命周期相同或相近的场景使用,以减少垃圾收集开销。
go1.22在标准库引入了一个实验性的arena,在这个的issue,发出来没多久笔者就看到了,其中看到“为多个goroutine使用同一个arena是非常低效的。当然,这通常也没有什么意义,因为在不同的goroutine中分配的object的生命周期可能非常不同”,这里笔者印象很深,因为当时读到,笔者立刻就想到了一个多goroutine使用同一个arena的场景,是编译器解析多个源文件成抽象语法树,所有的节点生命周期都是相同的,而且支持goroutine使用到底有多低效呢?所以笔者在go标准库外试着实现了一个支持多goroutine使用的arena.
当这里写在go标准库外实现比go标准库更好的arena,指的是
- 单goroutine使用性能更好
- 支持多goroutine使用
实现
基础实现
首先,准备一个持有一块内存的切片,和一个索引,称为buf,分配就是加索引,然后如果索引不大于长度,就获取这个切片这个索引的元素分配给调用者,不然就自动扩容,分配代码类似这样
index = index + 1
if index < len {
realloc()
}
return slice[index]
arena持有1个buf切片,最初里面有1个buf,它分配完就增加一个buf,以此类推,实现自动扩容。 一个简单的支持单goroutine的arena就是这么简单,后续就是在这基础上扩展。
分配一组object
go语言的切片类型可以表示一段内存,有n个T类型的object。 从arena分配一组object,利用这一点,可以比基础实现稍作修改,类似这样
index = index + num
if index < len {
realloc()
}
return slice[index-num:index]
真正支持分配任意类型
实现buf分配任意类型最简单的就是分配一个大的[]uint8,要几个字节索引就加几,然后对切片返回slice[oldindex]的地址,通过unsafe.Pointer返回对应地址的指针,就可以将这块内存当做任意类型的值来使用。一些其他人实现的arena可以极高效率的在单goroutine场景分配任意类型的秘诀正在于此。
这样做有一个问题,go语言的gc会把[]uint8视作不含有指针的类型,所以,如果这里存有一个指针,它对gc隐藏起来了,在极端情况,可能一个object只有被隐藏的一个指针引用,这意味着gc可能将正在使用的内存回收,稍后发生use-after-free,程序可能因此崩溃。
一种办法是分配[]unsafe.pointer,但是这样的buf只能分配全是指针的类型,否则gc看到指针类型的内存存着不是有效的指针,会引发程序崩溃。
得益于go1.18添加的泛型,可以分配一个[]T,T是任意类型,这样就可以像基础实现那样一个buf安全的分配一种类型的值。
然后持有多个buf的变成一个类型的内存池,一个arena持有这些内存池,实现支持分配任意类型的支持单goroutine的arena。
高性能的支持多goroutine
支持多goroutine本身不难,任何只支持单goroutine的操作,加一个互斥锁就可以变成支持多gorutine的,但意味着只有CPU只有一个核被利用,很低效。
简单的加一把读写锁也是不行的,从arena分配是写操作,读写锁适用于的是读多写少的场景。虽然arena获取特定类型的内存池,和从内存池获取多个buf的一个通常是最后一个正在使用的buf,在大多数时候是一个读操作,但注意,加读锁本身是通过原子加实现的,它是写操作,在多goroutine,随着竞争程度的增加,虽然因为使可以同时进行的读操作同时进行,性能比互斥锁更好,但还有提升的空间。
原子写操作在多goroutine场景对性能的影响也是不可小觑的,一个例子就是arena获取特定类型的内存池时,比使用读写锁,采用笔者前段时间的博客 “用原子指针+互斥锁实现仅写时加锁” 里描述的方法,消除了热路径上的一个原子写操作,多goroutine性能提升了约30%。
采用笔者前段时间的博客 “用原子指针+互斥锁实现仅写时加锁” 里描述的方法,程序根据是否大多数时候执行的代码路径,分为热路径和冷路径。
热路径是不需要自动扩容时,顺利从内存池当前正在使用的buf分配的代码路径,热路径上只有一个原子写操作,是buf加索引时,目前没有办法消除这个原子写操作,热路径其他用到的同步就是原子读,所以确保了笔者实现的arena高性能的支持goroutine。
支持重用内存
arena之所以能减少垃圾收集开销,在于它把一组生命周期相同或相似的object,一次全部释放,而这意味着有内存可以被立即重用,从而减少了gc运行的次数。顺带因此针对性实现,分配性能更好。如果只支持单gorutine,arena一次分配的性能开销可以压缩的一个加法,一个if判断,一个取地址,在大量分配小对象的场景,已经足以产生可观测的性能提升了。
arena支持重用的内存,在于真正持有了一块连续内存的buf,go语言标准库提供的sync.Pool可以用来重用buf,可以把buf放进去,等需要时再取出实现重用内存。
因为buf持有的内存大小不同,类型不同,所以将其放进sync.Pool,需要先找到同样类型的一些sync.Pool,在从中找到同样大小的sync.Pool,以确保安全的从同一个sync.Pool,得到的是同样类型持有同样大小内存的buf。
依靠go语言标准库的sync.Map,可以高效的做到这一点 这是笔者写的做到上述做法的代码,其中的MemBlock和上文中的buf表示同样的含义。
var globarPool sync.Map
func getMemBlockPool(rtype uintptr, bufSize int64) *sync.Pool {
m, have := globarPool.Load(rtype)
if !have {
m = new(sync.Map)
//无论是否成功,都说明同样类型的内存块的sync.Map有了
m, _ = globarPool.LoadOrStore(rtype, m)
}
typmap := m.(*sync.Map)
// 上面拿到了 每个类型不同的 sync.map , 里面有每个类型不同大小内存块的sync.Pool
p, _ := typmap.Load(bufSize)
// 上面尝试拿 放着同样类型同样大小内存块的 sync.Pool
blockp, have := p.(*sync.Pool)
if !have {
blockp = new(sync.Pool)
p, _ = typmap.LoadOrStore(bufSize, blockp)
// Note 这里的类型断言肯定成功,因为如果是写操作,得到的是刚刚的new(sync.Pool),
// 如果是读操作,读到的是其他goroutine写的new(sync.Pool)
blockp = p.(*sync.Pool)
}
// 上面拿到了 放着同样类型相同大小内存块的 sync.Pool
return blockp
}
给arena一个Free方法,当这个方法被调用时,将内存池的buf放入sync.Pool。 然后只需要再从arena分配时,要分配的类型的内存池首先尝试从sync.Pool获取buf,就实现了重用内存。
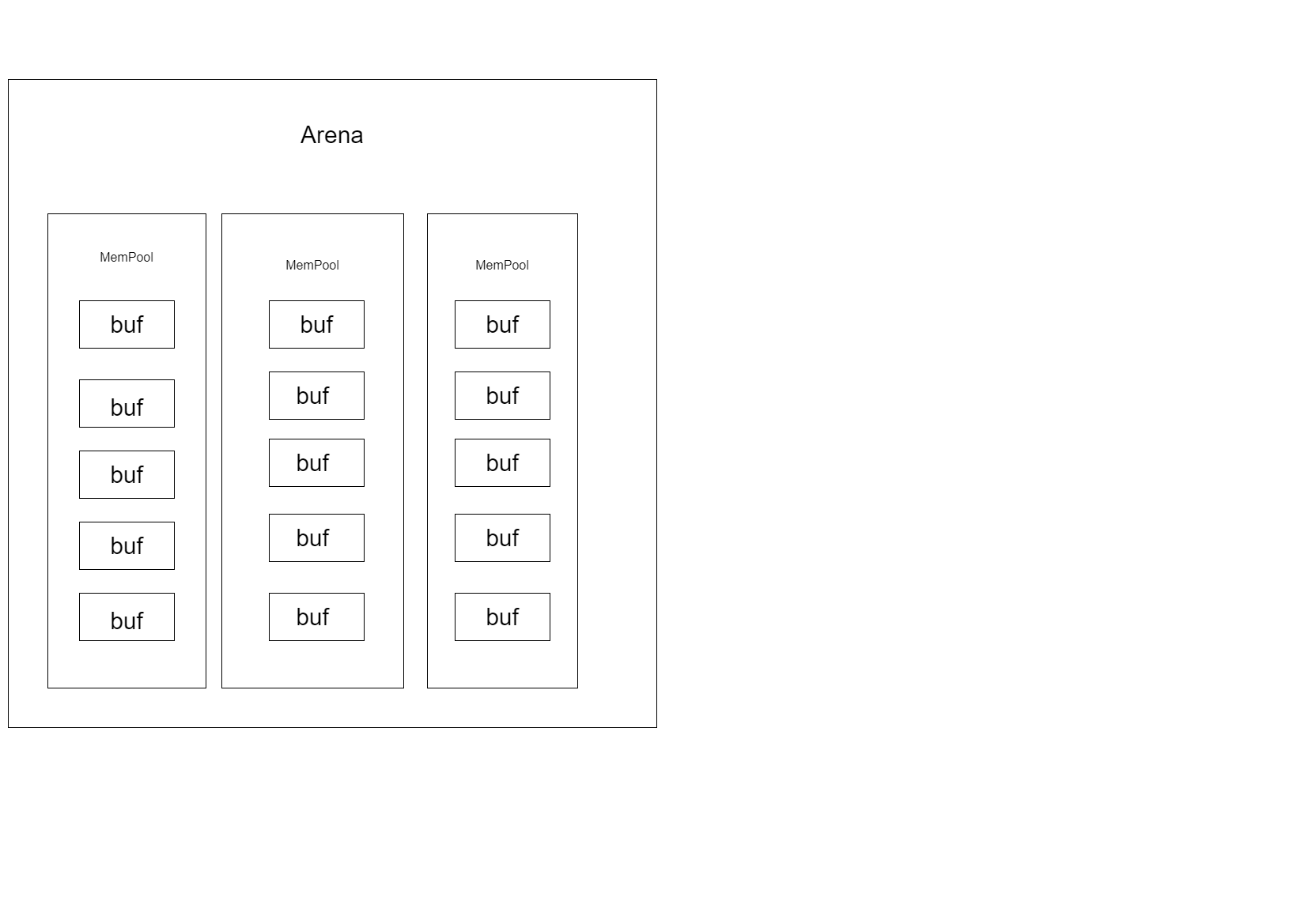
结构图
最终实现的arena结构如图所示
性能对比
从arena分配一个int:
笔者实现的:8.387 ns/op
go标准库的:9.299 ns/op
从arena分配100个int再free:
笔者实现的:965.7 ns/op
go标准库的:1079 ns/op
未来的优化
定制哈希表
当前,arena通过map持有不同类型的内存池,通常map的简单实现是 hash(key) % len,然后通用的map为了处理各种情况,有线性探测,链地址法等各种方法。在arena这个场景,这不是最优的。
针对arena的场景,key是一个指针,直接把这个指针转成整数,不需要哈希函数,直接,uintptr(key) % len,一条机器指令运算完成key变为index。而且因为基本查找都是成功,key的数量很少,简单的加上线性探测就可以。这样定制哈希表,可以提升性能。
分片
分片是减少共享写操作为主的值的争用的一种有用且常用的方法。
即使只是一个原子加,在多goroutine时对性能的影响也不可小觑,根据笔者尝试实现分片在go标准库的经验,同样的对int64加10000次1,如果所有的goroutine都在对同一个内存地址进行原子加,比所有的goroutine对8个不同的内存地址进行原子加,性能差了20多倍。仅仅是一个原子加,通过分片将对同一内存地址的争用分开,就有了显著的性能差异。
当前实现的热路径上还有一个原子加,通过分片,可以消除这个原子加。提升多goroutine使用arena的性能。
不返回零值
go语言new一个值默认是零值,例如new(int)返回一个int指针,指向的int是0。
各种arena的实现基本也都维持了这个特性。
如果不需要默认零值的话,可以放弃默认零值,获得性能提升。
例如如果从arena分配出的内存总是马上被使用,就没有必要返回零值,可以直接将未清理的内存分配出去,稍后调用者使用会给内存赋值的。这样节省将内存设置为零值的开销
源代码地址:https://github.com/qiulaidongfeng/arena
源代码地址:https://gitee.com/qiulaidongfeng/arena